How AI Stops the Next Big Flu Before It Starts
22. Februar 2020How AI Stops the Next Big Flu Before It Starts
New York, February 22, 2020
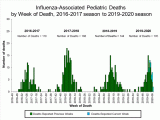
Immune systems around the world have been working overtime this winter as a devastating flu season has arrived. According to the Centers for Desease Control and Prevention CDC (see graphic above), more than 180,000 Americans have been hospitalized and 10,000 more have died in recent months, while the coronavirus (now officially known as COVID-19) is on the alarming rate at an alarming rate spread all over the world.
Fears of a globally growing outbreak of flu have even led to the consumer electronics fair 2020 being canceled as a precautionary measure – barely a week before it was due to open in Barcelona. In the near future, artificial intelligence-driven drug development could help produce vaccines and treatments quickly enough to stop the spread of deadly viruses before they mutate into global pandemics. (Read the report on : https://www.engadget.com/)
Traditional methods of developing drugs and vaccines are extremely inefficient. Researchers have to spend almost a decade painstakingly checking candidate molecules for candidate molecules using intensive trial-and-error techniques. According to a study by the Tufts Center for the Study of Drug Development in 2019, the development of a single drug treatment costs an average of $ 2.6 billion – more than twice as much as in 2003 – with only around 12 percent going into clinical Development happen, ever get FDA approval.
Dr. Eva-Maria Strauch, assistant professor of pharmaceutical and biomedical sciences at the University of Georgia, pointed out that „it takes the FDA five to ten years to approve a drug.“
However, with the help of machine learning systems, biomedical researchers can essentially turn the trial and error method upside down. Instead of systematically manually trying every possible treatment, researchers can use AI to sort large databases of candidate compounds and recommend those that are most likely to be effective.
„Many of the questions that drug development teams face are no longer the kind of questions that people think they can answer if they just sort data in their heads,“ said S. Joshua Swamidass, a computer biologist at Washington University The Scientist in 2019. „There must be a systematic way of looking at large amounts of data … to answer questions and gain insight into how to do it.“
For example, terbinafine is an oral antifungal drug that was marketed in 1996 as Lamifil, a treatment for thrush. However, within three years, several people had reported side effects from taking the drug, and by 2008 three people had died of liver toxicity and another 70 had become ill. The doctors determined that a metabolite of terbinafine (TBF-A) was the cause of the liver damage, but at the time were unable to find out how it was produced in the body.
This pathway remained a mystery to the medical community for a decade until, in 2018, Washington University doctoral student Na Le Dang trained a metabolic pathway AI and let the machine figure out how the liver could break down terbinafine into TBF-A. It turns out that the generation of the toxic metabolite is a two-step process, which is experimentally far more difficult to identify, but simple enough to be recognized by an AI’s powerful pattern recognition capabilities.
In fact, more than 450 drugs have been withdrawn from the market in the past 50 years, many of them due to the cause of liver toxicity such as Lamifil. Enough that the FDA launched the Tox21.gov website, an online database of molecules and their relative toxicity to various important human proteins. By training an AI with this data set, the researchers hope to be able to determine more quickly whether a possible treatment causes serious side effects or not.
Sam Michael, CIO of the National Center for the Promotion of Translational Sciences, said: „We have been asked several times in the past to predict the toxicity of these compounds.“ This prompted us to create the database. „This is exactly the opposite of what we’re doing for screening small molecules for drugs. We don’t want to find a hit, we want to say ‚Hey, chances are this [compound is toxic].‘ „
Artificial intelligence also helps develop a better flu vaccine. In 2019, researchers at Flinders University in Australia used an AI to „charge“ a common flu vaccine so that the body produced higher levels of antibodies when exposed. Technically speaking, the researchers did not even „use“ an AI, but switched it on and avoided it because it designed a vaccine entirely on its own.
The team, led by Flinders University’s medical professor Nikolai Petrovsky, first built the Sam (ligand search algorithm). Why they didn’t call it Sal is unclear. Sam is trained to distinguish between molecules that are effective against the flu and those that are not. The team then trained a second program to generate trillions of potential chemical compound structures and returned them to Sam so that he had to decide whether they would be effective or not. The team then took the top candidates and physically synthesized them. Subsequent animal studies confirmed that the augmented vaccine was more effective than its non-improved predecessor.
Initial human trials began in the U.S. at the beginning of the year and are expected to take approximately 12 months. If the approval process runs smoothly, the turbo-charged vaccine could be publicly available within a few years. Not bad for a vaccine that only took two years to develop (instead of the normal 5-10).
While machine learning systems can view enormous data sets much faster than biological researchers and can make accurate, well-founded estimates with far weaker connections, humans will remain in the loop of drug development for the foreseeable future. For one thing, who else will generate, assemble, index, organize, and label all of the training data required to teach an AI what to look for?
Even as machine learning systems become more competent, like any other AI, they are susceptible to sub-optimal results if they use incorrect or biased data. „Many of the data sets used in medicine come mainly from white, North American and European population groups,“ wrote Dr. Charles Fisher, founder and CEO of Unlearn.AI, in November. „If a researcher applies machine learning to any of these data sets and discovers a biomarker to predict response to therapy, there is no guarantee that the biomarker will work well, if at all, in a more diverse population.“ To counteract the distortion effects of data distortion, Fisher advocates „larger data sets, more sophisticated software and more powerful computers“.
Another key component is clean data. „In the past, we had the challenge of predicting the toxicity of these compounds in advance,“ said Kebotix CEO Dr. Jill Becker. Kebotix is a 2018 startup that uses AI in collaboration with robotics to design and develop exotic materials and chemicals.
„We have three data sources,“ she said. „We have the ability to generate our own data … think of semi-empirical calculations. We also have our own synthetic laboratory to generate data and then … use external data.“ This external data can come from either open or subscription journals, patents, and the company’s research partners. Regardless of the source, „we spend a lot of time cleaning it,“ Becker noted.
„It is extremely important to make sure that the data has the right metadata for these models,“ said Michael. „And it doesn’t just happen, you really have to make an effort. It’s difficult because it’s expensive and time-consuming.“