

Wie KI die nächste große Grippe stoppt, bevor sie beginnt
22. Februar 2020Wie KI die nächste große Grippe stoppt, bevor sie beginnt
New York, 22.2.2020
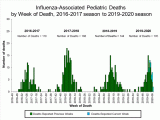
Immunsysteme auf der ganzen Welt haben diesen Winter Überstunden gemacht, da eine verheerende Grippesaison Einzug gehalten hat. Laut Centers for Desease Control and Prevention CDC (s. Grafik oben) wurden in den letzten Monaten mehr als 180.000 Amerikaner ins Krankenhaus eingeliefert und 10.000 weitere sind gestorben, während sich das Coronavirus (jetzt offiziell als COVID-19 bezeichnet) mit alarmierender Geschwindigkeit auf der ganzen Welt verbreitet hat.
Die Befürchtungen eines weltweit wachsenden Grippeausbruchs haben sogar dazu geführt, dass die Consumer Electronic- Messe 2020 vorsorglich abgesagt wurde – kaum eine Woche bevor sie in Barcelona eröffnet werden sollte. In naher Zukunft könnte die mit Hilfe der künstlichen Intelligenz forcierte Arzneimittelentwicklung dazu beitragen, Impfstoffe und Behandlungen schnell genug herzustellen, um die Ausbreitung tödlicher Viren zu stoppen, bevor sie zu globalen Pandemien mutieren, berichtet das Portal https://www.engadget.com/
Herkömmliche Methoden zur Entwicklung von Arzneimitteln und Impfstoffen sind äußerst ineffizient. Forscher müssen fast ein Jahrzehnt damit verbringen, Kandidatenmoleküle nach Kandidatenmolekülen mithilfe intensiver Trial-and-Error-Techniken mühsam zu überprüfen. Laut einer Studie des Tufts Center for the Study of Drug Development aus dem Jahr 2019 kostet die Entwicklung einer einzelnen Arzneimittelbehandlung durchschnittlich 2,6 Milliarden US-Dollar – mehr als doppelt so viel wie 2003 -, wobei nur rund 12 Prozent, die in die klinische Entwicklung eintreten, jemals die FDA-Zulassung erhalten .
Dr. Eva-Maria Strauch, Assistenzprofessorin für Pharmazeutische und Biomedizinische Wissenschaften an der University of Georgia, wies darauf hin, dass „die FDA wirklich fünf bis zehn Jahre braucht, um ein Medikament zuzulassen.“
Mit Hilfe von maschinellen Lernsystemen können biomedizinische Forscher die Trial-and-Error-Methode jedoch im Wesentlichen auf den Kopf stellen. Anstatt jede mögliche Behandlung systematisch manuell zu versuchen, können Forscher mithilfe einer KI umfangreiche Datenbanken mit Kandidatenverbindungen sortieren und diejenigen empfehlen, die am wahrscheinlichsten wirksam sind.
„Viele der Fragen, mit denen sich Arzneimittelentwicklungsteams konfrontiert sehen, sind nicht mehr die Art von Fragen, die die Leute zu beantworten glauben, wenn sie nur Daten in ihren Köpfen sortieren“, sagte S. Joshua Swamidass, ein Computerbiologe an der Washington University The Scientist im Jahr 2019. „Es muss eine systematische Art geben, große Datenmengen zu betrachten … um Fragen zu beantworten und Einblicke in die Vorgehensweise zu erhalten.“
Zum Beispiel ist Terbinafin ein orales Antimykotikum, das 1996 als Lamifil, eine Behandlung gegen Soor, vermarktet wurde. Innerhalb von drei Jahren hatten jedoch mehrere Personen Nebenwirkungen der Einnahme des Medikaments gemeldet, und bis 2008 waren drei Personen an Lebertoxizität gestorben und weitere 70 waren krank geworden. Die Ärzte stellten fest, dass ein Metabolit von Terbinafin (TBF-A) die Ursache für den Leberschaden war, konnten jedoch zu diesem Zeitpunkt nicht herausfinden, wie er im Körper produziert wurde.
Dieser Stoffwechselweg blieb der medizinischen Gemeinschaft ein Jahrzehnt lang ein Rätsel, bis 2018 die Doktorandin der Washington University, Na Le Dang, eine KI für Stoffwechselwege trainierte und die Maschine herausfinden ließ, wie die Leber Terbinafin in TBF-A zerlegen könnte . Es stellt sich heraus, dass die Erzeugung des toxischen Metaboliten ein zweistufiger Prozess ist, der experimentell weitaus schwieriger zu identifizieren ist, aber einfach genug, um von den leistungsstarken Mustererkennungsfähigkeiten einer KI erkannt zu werden.
Tatsächlich wurden in den letzten 50 Jahren mehr als 450 Medikamente vom Markt genommen, viele davon wegen der Verursachung von Lebertoxizität wie Lamifil. Genug, dass die FDA die Website Tox21.gov gestartet hat, eine Online-Datenbank mit Molekülen und ihrer relativen Toxizität gegenüber verschiedenen wichtigen menschlichen Proteinen. Durch das Training einer KI mit diesem Datensatz hoffen die Forscher, schneller feststellen zu können, ob eine mögliche Behandlung schwerwiegende Nebenwirkungen verursacht oder nicht.
Sam Michael, CIO des Nationalen Zentrum für die Förderung der translationalen Wissenschaften, berichtet: „Wir wurden in der Vergangenheit mehrfach gebete, die Toxizität dieser Verbindungen im Voraus vorherzusagen“. Das hat uns veranlasst, die Datenbank zu erstellen. „Dies ist genau das Gegenteil von dem, was wir für das Screening kleiner Moleküle auf Arzneimittel tun. Wir wollen keinen Treffer finden, wir wollen sagen ‚Hey, es besteht die Wahrscheinlichkeit, dass diese [Verbindung toxisch] ist.'“
Künstliche Intelligenz hilft auch bei der Entwicklung eines besseren Grippeimpfstoffs. Im Jahr 2019 verwendeten Forscher der Flinders University in Australien eine KI, um einen gängigen Grippeimpfstoff „aufzuladen“, damit der Körper bei Exposition höhere Antikörperkonzentrationen produziert. Technisch gesehen „verwendeten“ die Forscher eine KI nicht einmal, sondern schalteten sie ein und gingen ihr aus dem Weg, da sie einen Impfstoff völlig eigenständig entwarf.
Das Team unter der Leitung des Medizinprofessors der Flinders University, Nikolai Petrovsky, baute zunächst den Sam (Suchalgorithmus für Liganden). Warum sie es nicht Sal nannten, ist ungeklärt. Sam ist darauf trainiert, zwischen Molekülen, die gegen die Grippe wirksam sind, und solchen, die es nicht sind, zu unterscheiden. Das Team trainierte dann ein zweites Programm, um Billionen potenzieller Strukturen chemischer Verbindungen zu generieren, und gab diese an Sam zurück, so das er entscheiden musste, ob sie wirksam sein würden oder nicht. Das Team nahm dann die Spitzenkandidaten und synthetisierte sie physikalisch. Nachfolgende Tierversuche bestätigten, dass der Augmented-Impfstoff wirksamer war als sein nicht verbesserter Vorgänger.
Erste Versuche am Menschen begannen in den USA zu Beginn des Jahres und werden voraussichtlich etwa 12 Monate dauern. Sollte der Zulassungsprozess reibungslos verlaufen, könnte der turbogeladene Impfstoff innerhalb weniger Jahre öffentlich verfügbar sein. Nicht schlecht für einen Impfstoff, dessen Entwicklung nur zwei Jahre dauerte (anstatt der normalen 5 – 10).
Während maschinelle Lernsysteme enorme Datensätze viel schneller als biologische Forscher sichten und genaue fundierte Schätzungen mit weitaus schwächeren Zusammenhängen vornehmen können, wird der Mensch auf absehbare Zeit in der Schleife der Arzneimittelentwicklung bleiben. Zum einen, wer sonst wird alle Trainingsdaten generieren, zusammenstellen, indizieren, organisieren und kennzeichnen, die erforderlich sind, um einer KI beizubringen, wonach sie suchen sollen?
Selbst wenn maschinelle Lernsysteme kompetenter werden, sind sie wie bei jeder anderen KI anfällig für suboptimale Ergebnisse, wenn sie fehlerhafte oder voreingenommene Daten verwenden. „Viele in der Medizin verwendete Datensätze stammen hauptsächlich aus weißen, nordamerikanischen und europäischen Bevölkerungsgruppen“, schrieb Dr. Charles Fisher, Gründer und CEO von Unlearn.AI, im November. „Wenn ein Forscher maschinelles Lernen auf einen dieser Datensätze anwendet und einen Biomarker entdeckt, um das Ansprechen auf eine Therapie vorherzusagen, gibt es keine Garantie dafür, dass der Biomarker in einer vielfältigeren Population, wenn überhaupt, gut funktioniert.“ Um den Verzerrungseffekten der Datenverzerrung entgegenzuwirken, plädiert Fisher für „größere Datensätze, ausgefeiltere Software und leistungsfähigere Computer“.
Eine weitere wesentliche Komponente sind saubere Daten. „Wir hatten in der Vergangenheit die Herausforderung, die Toxizität dieser Verbindungen im Voraus vorherzusagen“ erklärte Kebotix-CEO Dr. Jill Becker . Kebotix ist ein Startup aus dem Jahr 2018, das KI in Zusammenarbeit mit Robotik einsetzt, um exotische Materialien und Chemikalien zu entwerfen und zu entwickeln.
„Wir haben drei Datenquellen“, erklärte sie. „Wir haben die Fähigkeit, unsere eigenen Daten zu generieren … denken Sie an semi-empirische Berechnungen. Wir haben auch unser eigenes synthetisches Labor, um Daten zu generieren und dann … externe Daten zu verwenden.“ Diese externen Daten können entweder aus offenen oder Abonnement-Journalen sowie aus Patenten und den Forschungspartnern des Unternehmens stammen. Unabhängig von der Quelle „verbringen wir viel Zeit damit, es zu reinigen“, bemerkte Becker.
„Es ist absolut wichtig, sicherzustellen, dass den Daten die richtigen Metadaten für diese Modelle zugeordnet sind“, mischte sich Michael ein. „Und es passiert nicht nur, man muss sich wirklich anstrengen. Es ist schwierig, weil es teuer und zeitaufwändig ist.“

klingt hochinteressant und vielversprechend, hoffen wir das Beste…
und was wird der Impfstoff kosten??