„Text-zu-Bild-Modelle sind spannende Werkzeuge für Inspiration und Kreativität.“
30. Juni 2022„Text-zu-Bild-Modelle sind spannende Werkzeuge für Inspiration und Kreativität.“
San Francisco, 30.6.2022
Forscher des Suchmaschinengiganten Google haben kürzlich bekannt gegeben, sie hätten mit einer Reihe von KI-Techniken eine neuartige Technologie des maschinellen Lernens entwickelt – die so genannte Text-zu-Bild-Generierung. Diese Modelle können aus einer einfachen Texteingabe hochwertige, fotorealistische Bilder erzeugen.
Nach zahlreichen Tests konnten sie zwei neue Text-zu-Bild-Modelle präsentieren – Imagen und Parti. Beide sind in der Lage, fotorealistische Bilder zu erzeugen, verwenden aber unterschiedliche Ansätze.
Wie Text-zu-Bild-Modelle funktionieren
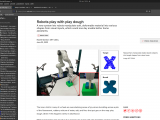
Bei Text-Bild-Modellen geben die Benutzer eine Textbeschreibung ein, und die Modelle erzeugen Bilder, die dieser Beschreibung so genau wie möglich entsprechen. Das kann etwas so Einfaches sein wie „ein Apfel“ oder „eine Katze sein. Doch auch komplexere Details wie „Aus der Truhe kommt ein helles, goldenes Leuchten“, können verarbeitet werden.
Die Forscher erwähnen, dass „ML-Modelle auf großen Bilddatensätzen mit entsprechenden Textbeschreibungen trainiert“ wurden. Das habe die Qualität der Bilder verbessert und zu einem breiteren Spektrum an Beschreibungen geführt . Als bedeutende Durchbruch bezeichnen die Ägooge lianer Googelianer DALL-E 2 von Open AI.
Wie Imagen und Parti funktionieren beschreiben die Forscher so:
„Imagen und Parti sind eine Weiterentwicklug und bauen auf früheren Modellen auf. Transformer-Modelle sind in der Lage, Wörter im Verhältnis zueinander in einem Satz zu verarbeiten. Sie sind die Grundlage dafür, wie wir Text in unseren Text-Bild-Modellen darstellen. Beide Modelle verwenden außerdem eine neue Technik, mit deren Hilfe Bilder erzeugt werden, die der Textbeschreibung besser entsprechen. Während Imagen und Parti eine ähnliche Technologie verwenden, verfolgen sie unterschiedliche, aber komplementäre Strategien.
Imagen ist ein Diffusionsmodell, das lernt, ein Muster aus zufälligen Punkten in Bilder umzuwandeln. Diese Bilder beginnen mit einer niedrigen Auflösung und werden dann schrittweise immer höher aufgelöst. In letzter Zeit waren Diffusionsmodelle sowohl bei Bild- als auch bei Audioaufgaben erfolgreich, z. B. bei der Verbesserung der Bildauflösung, der Neueinfärbung von Schwarz-Weiß-Fotos, der Bearbeitung von Bildbereichen, dem Freistellen von Bildern und der Synthese von Text in Sprache.
Der Ansatz von Parti wandelt zunächst eine Sammlung von Bildern in eine Folge von Code-Einträgen um, ähnlich wie Puzzleteile. Eine gegebene Textaufforderung wird dann in diese Code-Einträge übersetzt, und ein neues Bild wird erstellt. Dieser Ansatz nutzt die Vorteile der bestehenden Forschung und Infrastruktur für große Sprachmodelle wie PaLM und ist entscheidend für die Verarbeitung langer, komplexer Texteingaben und die Erzeugung hochwertiger Bilder.“
Dennoch: perfekt sind diese Modelle keineswegs. Die Forscher weisen darauf hin, das sie „weder die Anzahl der Objekte (z. B. „zehn Äpfel“) noch deren korrekte Platzierung auf der Grundlage bestimmter räumlicher Beschreibungen (z. B. „eine rote Kugel links von einem blauen Block mit einem gelben Dreieck darauf“) zuverlässig ermitteln“ können. Auf komplexere Aufforderungen reagieren sie ebenfalls fehlerhaft.
/
„Text-zu-Bild-Modelle sind spannende Werkzeuge für Inspiration und Kreativität.“ Doch man möge sich nicht täuschen. Es gebe nämlich „Risiken in Bezug auf Desinformation, Voreingenommenheit und Sicherheit.“
Die Google– Forscher diskutieren darum „über verantwortungsvolle KI-Praktiken und die notwendigen Schritte, um diese Technologie sicher einzusetzen. In einem ersten Schritt verwenden wir leicht identifizierbare Wasserzeichen, um sicherzustellen, dass die Menschen ein von Imagen oder Parti generiertes Bild immer erkennen können. Wir führen auch Experimente durch, um die Verzerrungen der Modelle, z. B. bei der Darstellung von Menschen und Kulturen, besser zu verstehen und mögliche Abhilfemaßnahmen zu erforschen. In den Papieren von Imagen und Parti werden diese Fragen ausführlich erörtert“.
Wie geht es weiter mit den Text-Bild-Modellen bei Google?
„Wir werden neue Ideen vorantreiben, die das Beste aus beiden Modellen vereinen, und uns mit verwandten Aufgaben befassen, z. B. mit der Möglichkeit, Bilder interaktiv durch Text zu erzeugen und zu bearbeiten. Außerdem führen wir weiterhin eingehende Vergleiche und Bewertungen durch, um unsere Grundsätze für verantwortungsvolle KI zu erfüllen. Unser Ziel ist es, auf diesen Modellen basierende Nutzererfahrungen auf sichere, verantwortungsvolle und kreativitätsfördernde Weise in die Welt zu bringen“.